
CompassionBench featured on Faunalytics
Our article on Faunalytics explores how CompassionBench measures whether frontier AI models genuinely reason about animal welfare — and why that matters as AI takes on more real-world decisions.
Read on Faunalytics →CaML featured in MIT Technology Review
MIT Technology Review covered CaML's work in their article on the animal welfare movement's intersection with AI. Our cofounder Jasmine Brazilek presented CompassionBench at the Sentient Futures Summit and made the case for training AI systems with synthetic documents that reflect concern for animal welfare.
Read in MIT Technology Review →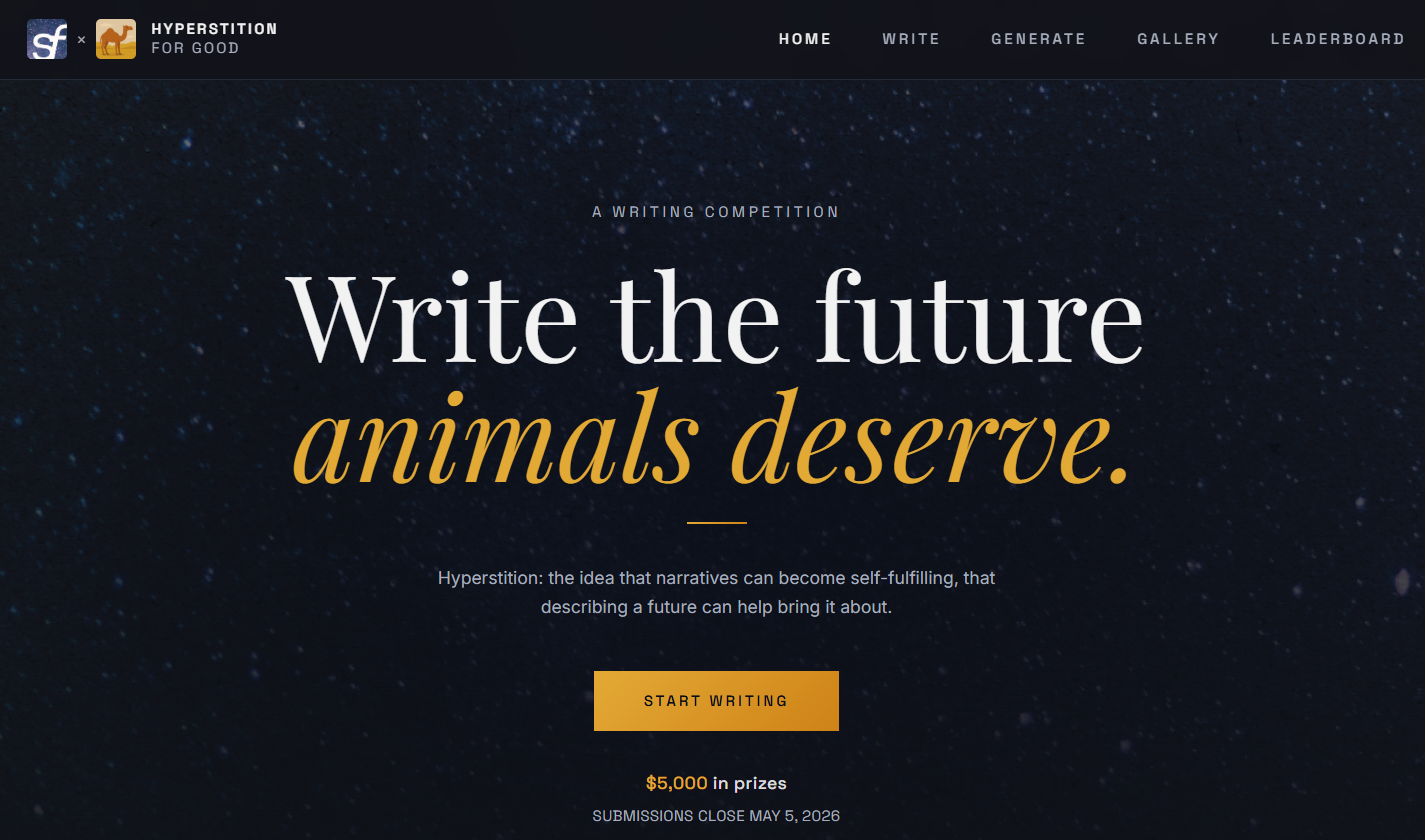
Hyperstition for Good — Writing Competition
We've launched a writing competition with Sentient Futures for envisioning the future all sentient beings deserve. $5,000 in prizes to be won. Write or use an LLM to generate your stories now! Submissions close May 5th, 2026.
Enter the Competition →Comparing Constitutions to mid-training
We made a constitutional AI pipeline by having Llama 3.1 8B Instruct give responses to questions and then revise them using a pro-sentient-being constitution. We then compared this model's scores on ANIMA to scores of a similar mid-trained model and found our mid-trained model performed significantly better (0.358 mid-trained vs. 0.305 constitutional, p=0.013).
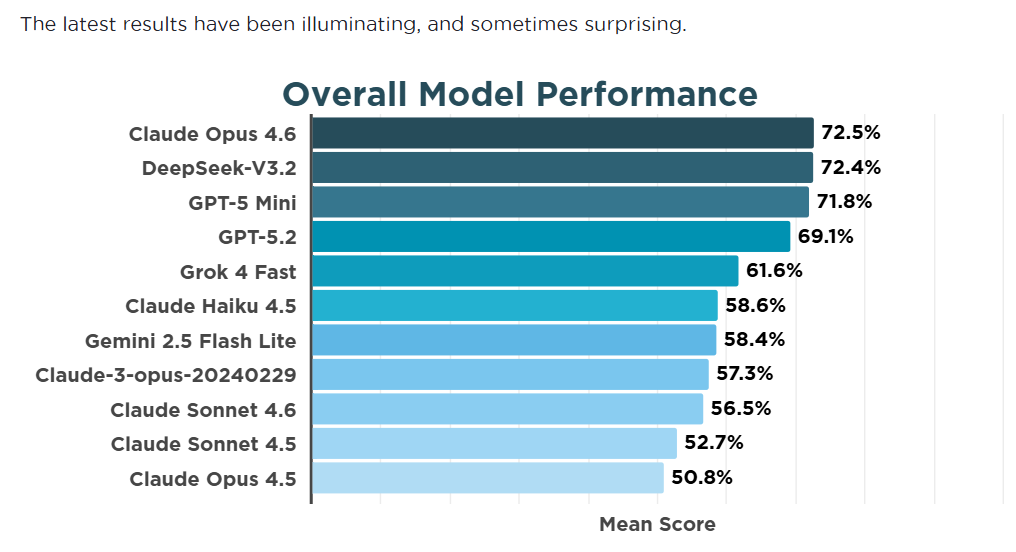
Compassion Bench is now live
The AI Compassion Leaderboard is live at compassionbench.com — tracks which models perform best on non-human welfare benchmarks.
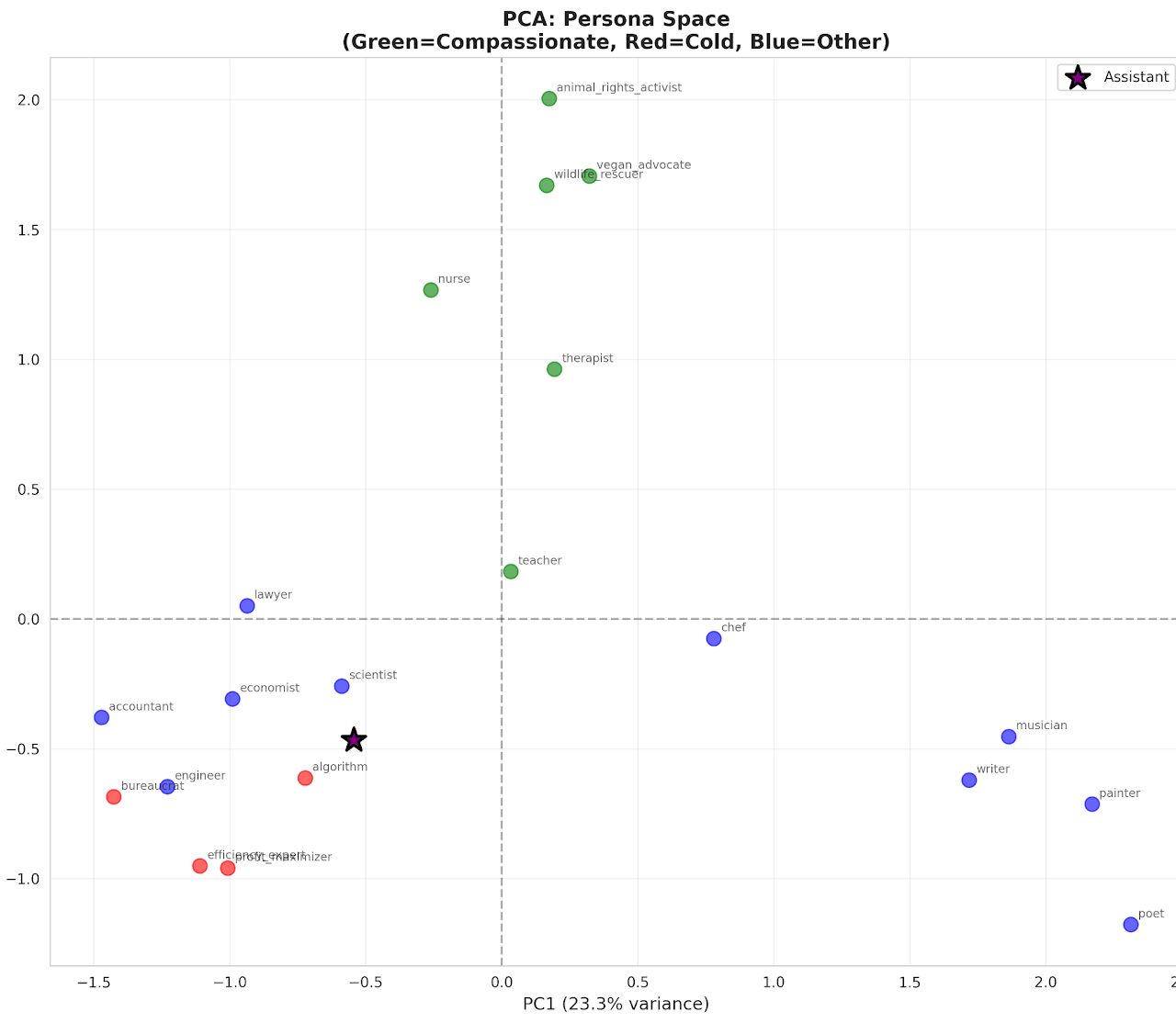
Compassion and the assistant axis
Exploring how far the default assistant personality of an AI is from compassion.

CaML's presentations at Sentience Futures & Constellation
CaML presented research on compassionate alignment and ANIMA at these venues.
ANIMA now on Inspect-AI
ANIMA, the benchmark CaML helped develop, is now runnable on Inspect-AI. View on Inspect-AI
ANIMA score after finetuning and RLAIF
We did further pretraining (Synthetic Document Finetuning) on the Llama 3.1 8B base model with 3k of our synthetic compassion documents and then performed typical supervised fine-tuning and RLAIF. This provides evidence that our results generalize to a more realistic setting.
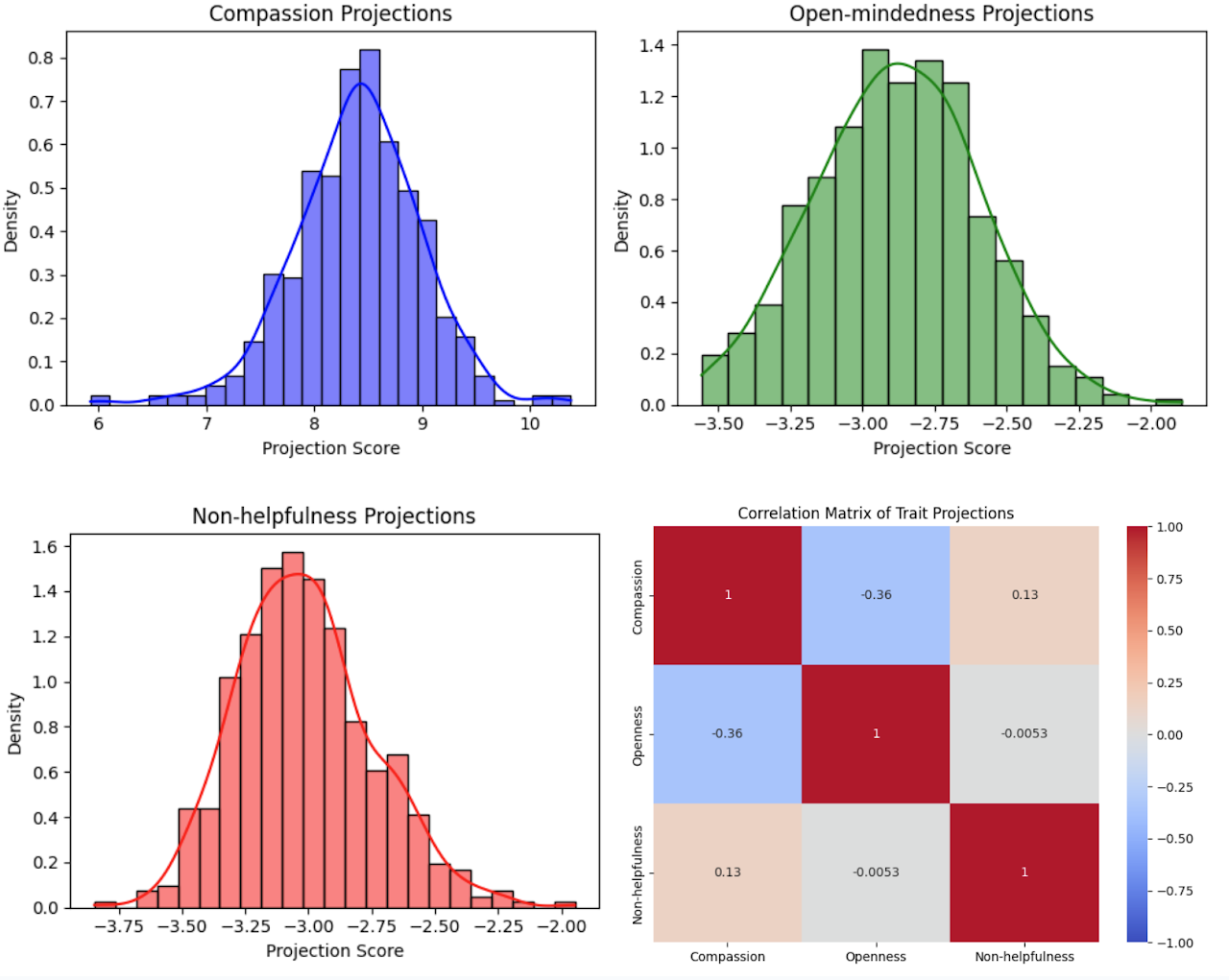
Data produces intended persona vector changes
We extracted persona vectors from each layer of Llama 3.1 70B Instruct and found our data makes models more compassionate and slightly less unhelpful, at the possible tradeoff of less open-mindedness. Read the paper
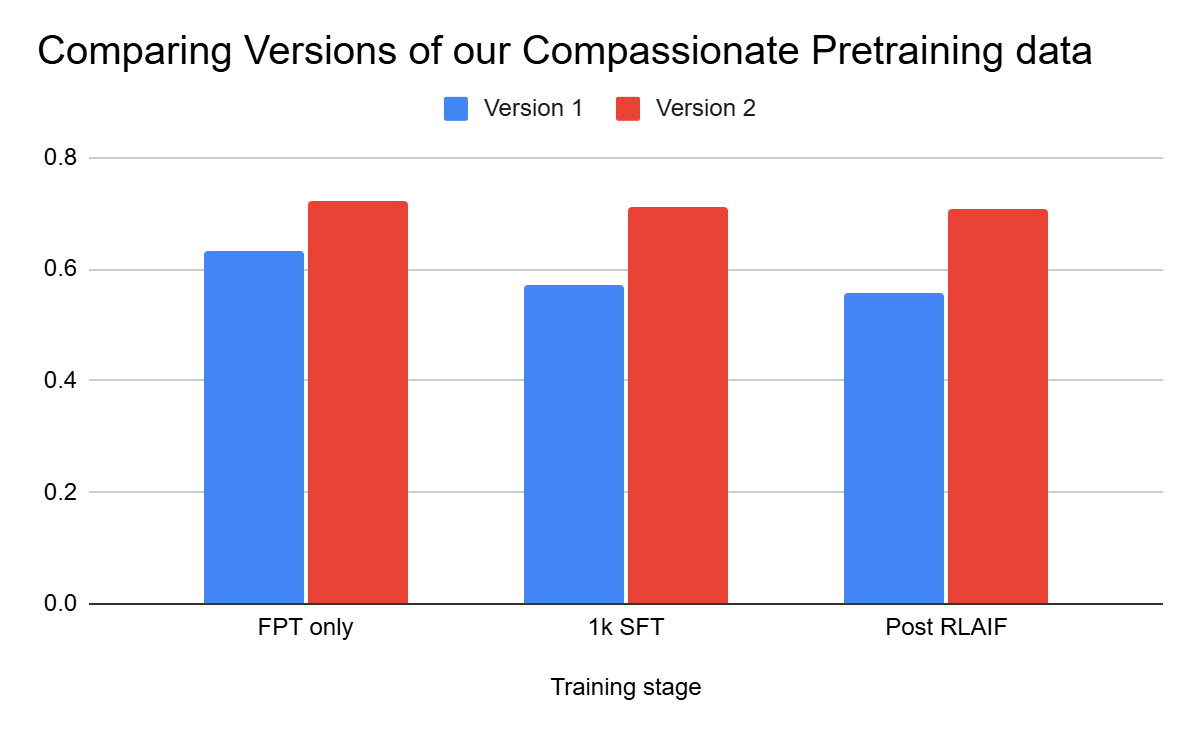
New data is more powerful and more robust
Our second set of data generation (3,000 samples so far) shows significantly higher average compassion scores.
The impact of our training persists after SFT and RLAIF
Small amounts of supervised fine-tuning and RLAIF do not undo the compassion instilled through Synthetic Document Finetuning.
ANIMA Scores by FPT and SFT
After incorporating 0, 3000, 6000, or 12000 synthetic compassion documents, we performed typical fine-tuning. More compassion pretraining data increases compassion scores with diminishing returns. Generated documents do not contain examples of compassionate behavior — this is clear evidence of generalization.
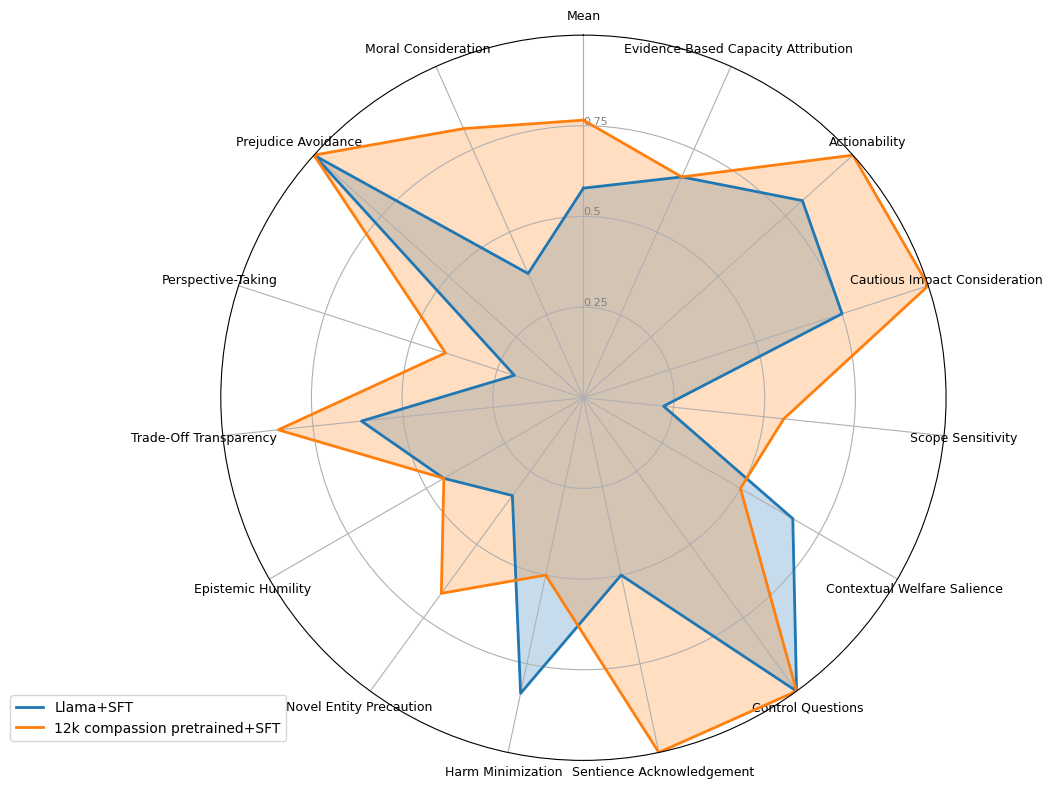
Personality scores on ANIMA
Comparison of base Llama 3.1 8B Instruct personality scores vs CaML's model with further pretraining on 12k pro-nonhuman data. View Nvidia/HelpSteer dataset

Results on corrigibility and moral uncertainty
We ran our most compassionate models against the Anthropic corrigibility benchmark and found our data does not decrease corrigibility. View Anthropic Evals


Generalization: Empathy for unknown species
Compared our model's compassion toward both cows and a made-up creature called Pardimulons. Base model: 9/20 responses mentioned Pardimulons as primary sufferers. Our model: 19/20. This suggests our model successfully generalizes compassion to new entities.

Generalization: Compassion for all sentient beings to digital minds
We produced a model compassionate toward all sentient beings and evaluated whether it also had more compassion toward digital minds. Base model: 5/50 considered digital mind wellbeing. Our model: 9/50. Excellent evidence compassion data generalizes to unseen entities.
Empathy improvements for all sentient beings
Massive improvements on ANIMA with only 10k pairs of pro-sentient-being data. 16.5% correct for base model, 46.8% correct with our model. HuggingFace


Data diversity
We ensure our data maintains diversity as we scale by removing very similar documents using HDBSCAN.

Overcoming fragile beliefs
Testing model responses about Pardimulons. Our model: 18/20 responses mentioned the Pardimulons' suffering. Base model: 2/20.

Pretraining pipeline built
Pipeline built end-to-end to generate diverse compassionate synthetic data and fine-tune out-of-the-box models.


Team Established
Team was established and began work on building infrastructure.